


A Practical Guide to Data Modeling
Understand the data modeling and the criteria for developing an optimal data model for mongoDB database.


Introduction
We all know, data is the essential element of an software application and stored into a database. To develop a better application we should develop some rules that can connect all these data and create useful and manageable information for our application. Developing such kinds of rules is called Data Modeling. Let's discuss more about this topic.
Data Modeling
Suppose we want to build a movie rating application. To build this we have to collect some real world data about movies, ratings, actors, directors and lots of things. But these real world data are unstructured and don't contain any connection with each other.
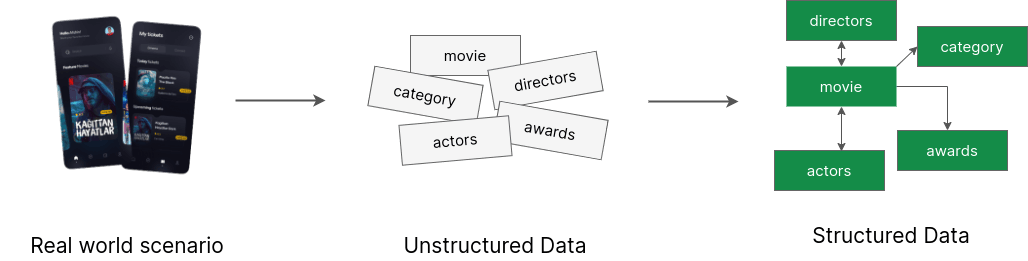
Without connection and relation it is difficult to maintain and manage data for this kind of application. That’s why we have to make this data structured. In simple words, the process that we used to make a structured dataset from an unstructured dataset is called Data modeling. So, "Data modeling is the process of taking unstructured data generated by a real world scenario and making it structured into a logical data model according to a set of criteria." To develop a better data model we need to learn first about Embedding or Denormalization and Referencing or Normalization and then some criteria for deciding when to embed and when to reference.
Embedding and Referencing
In mongoDB we can store data in both referencing and embedding format. But what is referencing and embedding 🤔 ? Lets dive into it...
01. Embedded Documents :
Embedded documents are stored as children inside a parent document. This means they are stored under one collection. If we fetch the parent document, the child or the embedded document also comes with it. It is an efficient and clean way to store related data, especially data that's regularly accessed together.
// Stored into movies collection & actors are embedded into it
[
{
_id: 1,
"name": "Se7en",
"actors": [
{
"name": "Morgan Freeman",
"age": 85,
"height": "1.88m"
},
{
"name": "Brad Pitt",
"age": 58,
"height": "1.80m"
}
}
]
- Pros: We can get all the information in one query
- Cons: Impossible to query the embedded documents on its own
02. Referenced Documents :
Referenced documents are stored in a separate collection to their parent document. Therefore, it’s possible to retrieve the parent document without retrieving any of its referenced documents.
// Stored into movies collection
[
{
_id: 1,
"name": "Se7en",
"actors": [
ObjectID(337),
ObjectID(590)
]
}
]
// Stored into actors collection
[
{
_id: 337,
"name": "Morgan Freeman",
"age": 85,
"height": "1.88m"
},
{
_id: 590,
"name": "Brad Pitt",
"age": 58,
"height": "1.80m"
}
]
- Pros: It’s easier to query each document on its own.
- Cons: We need two queries to get data from the referenced document.
When to embed and when to reference
There aren’t any general rules for selecting embedded or referenced but some suggestions. We can consider three main aspects for making decisions about whether we choose embedded or referenced data models. These are :
- Relationship type
- Data access patterns
- Data closeness
🔔 NOTE : We have to consider all of them for making the right decision, not only one of them in isolation. That means if criteria number one says to embed doesn’t mean that we don’t need to look at other two criteria. Now, let's discuss all these criteria.
01. Relationship Type :
To decide whether we embed our data or use referencing first we have to focus on how data are related to each other.
- If data collection has one-to-one or one-to-few then we can embed the data set into the main data set.
- For one to many relationships we can do either embed or reference. In that case we will have to decide the other two criteria.
- For one-to-ton or many-to-many relationships we actually reference the data. This is because if we did embed in this case, when data grow we could quickly create way too large document. Even potentially surpassing the maximum of 16 megabytes.
Okay now consider, We have around 100 images associated with each movie. But are we gonna embed the dataset or should we rather reference them here. Well we don’t know. So let's take a look at the other two criteria.
02. Data Access Patterns :
Data access patterns means whether a certain dataset is mostly written to or mostly read from.
- If the dataset that we are mostly used for read also the data is not updated a lot then we should embed that dataset. A data set that has a high read/write ratio ( it means mostly used for read ) is a good candidate for embedding. It is because we just need one query to fetch all the data that we need. This makes the process way more performant. So our movie images ( the situation that is described above ) would be a good candidate for embedding. This is because when 100 images for a movie are saved in a database they are not really updated anymore.
- If the dataset is updated a lot then we should consider referencing or normalization. That is because it needs more work for the database engine to update an embedded document than a more simple standalone referenced document. Since our main goal is performance, we just normalize the database in that case. So, A dataset that has a low read/write ratio ( mostly write that read ) is a good candidate for referencing. In our example let's say each movie has many reviews and each review can be marked as helpful by the user. So, each time someone clicked on this review was helpful in our application. We need to update the corresponding document. This means, the data can update all the time. So, this is a great candidate for normalizing or referencing.
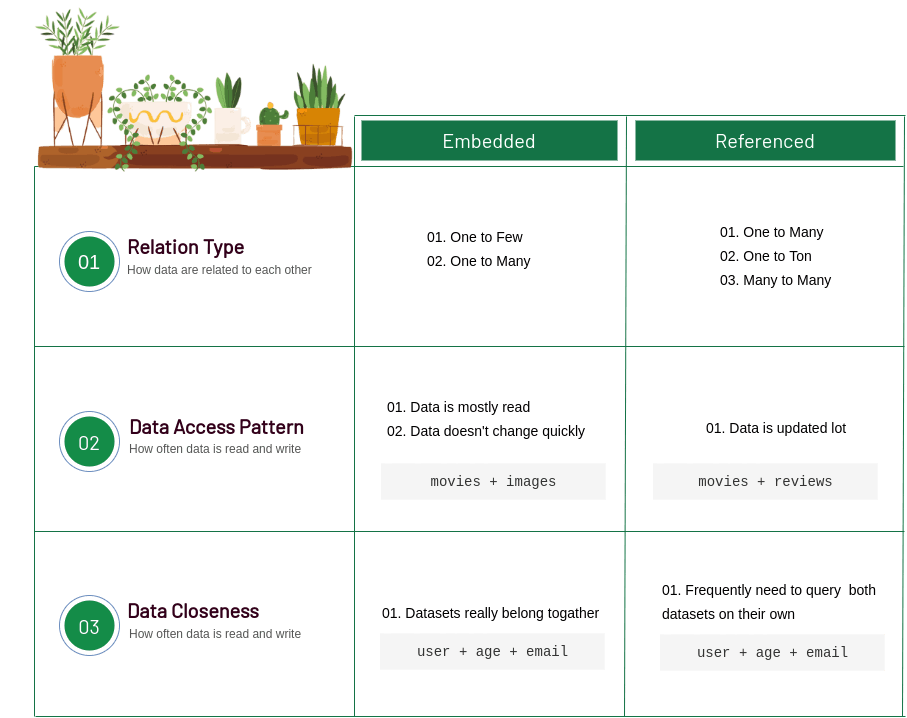
03. Data Closeness :
Data closeness is just a measure for how much the data are related. So
- If two datasets really intrinsically belong together then they should probably be embedded into one another. Suppose in our application age, email addresses are related to user data. That means age & email addresses are so intrinsically connected to the user. So in that case age & email address ( could be multiple ) data can be embedded into the user document.
- In case, we need to frequently update some data that is so closely related to another data, then it will be a great choice to choose referencing rather than embedding.
Conclusion
Data modeling is the crucial part of a software application because performance, maintainability, scalability and all the major quality related aspects depend on a good data model. There aren't any completely wrong or completely right ways of data modeling. I want to say the above discussions aren't any hard rules; these are only just guidelines to develop an optimal data model.
Reference
Node.js, Express, MongoDB & More: The Complete Bootcamp 2022 by Jonas Schmedtmann | From: udemy.com/course/nodejs-express-mongodb-boo..